In our last post, we introduced Recogito, a tool we built to verify and correct the results of our automatic text-to-map conversion process. Last time, we've focused primarily on Recogito's map-based interface, in which we clean up the results of geo-resolution - the step that automatically assigns gazetteer IDs to toponyms.
In this post, we want to talk about Recogito's second view: the text annotation interface. And as usual, we'd like to seize the opportunity to introduce our next Early Geospatial Document along with it: the Natural History by Pliny the Elder.
Naturalis Historia
The Natural History (Naturalis Historia) by Pliny the Elder is an encyclopedia published ca. AD 77–79. This amazing work covers the Roman civilization's knowledge about astronomy, geography, zoology, botany, medicine and mineralogy. In total, it consists of 37 books, and builds on more than 400 sources from the Latin and Greek worlds. Books 3, 4, 5 and 6 focus on geography. In these books, Pliny describes the known world from the Atlantic to the Near East, and from the North of Europe to Africa. He records all the peoples and cities known, with all the geographic features prominent in each territory, such as rivers, mountains, gulfs, or islands.

Fig. 1. Pliny Books 3 and 4 - work in progress in Recogito.
Recogito Text Annotation UI
The Natural history is the largest text we have addressed so far. Fig.1 shows our current progress with it. (In numbers, we're through the toponyms of Book 3 by 98%, and have just started Book 4 - now at 5.5%). It also differs from our previous itinerary texts, in the sense that it's prose, and not structured into an almost 'tabular' format. Time to enter our 'reading view' in Recogito: the text annotation interface.
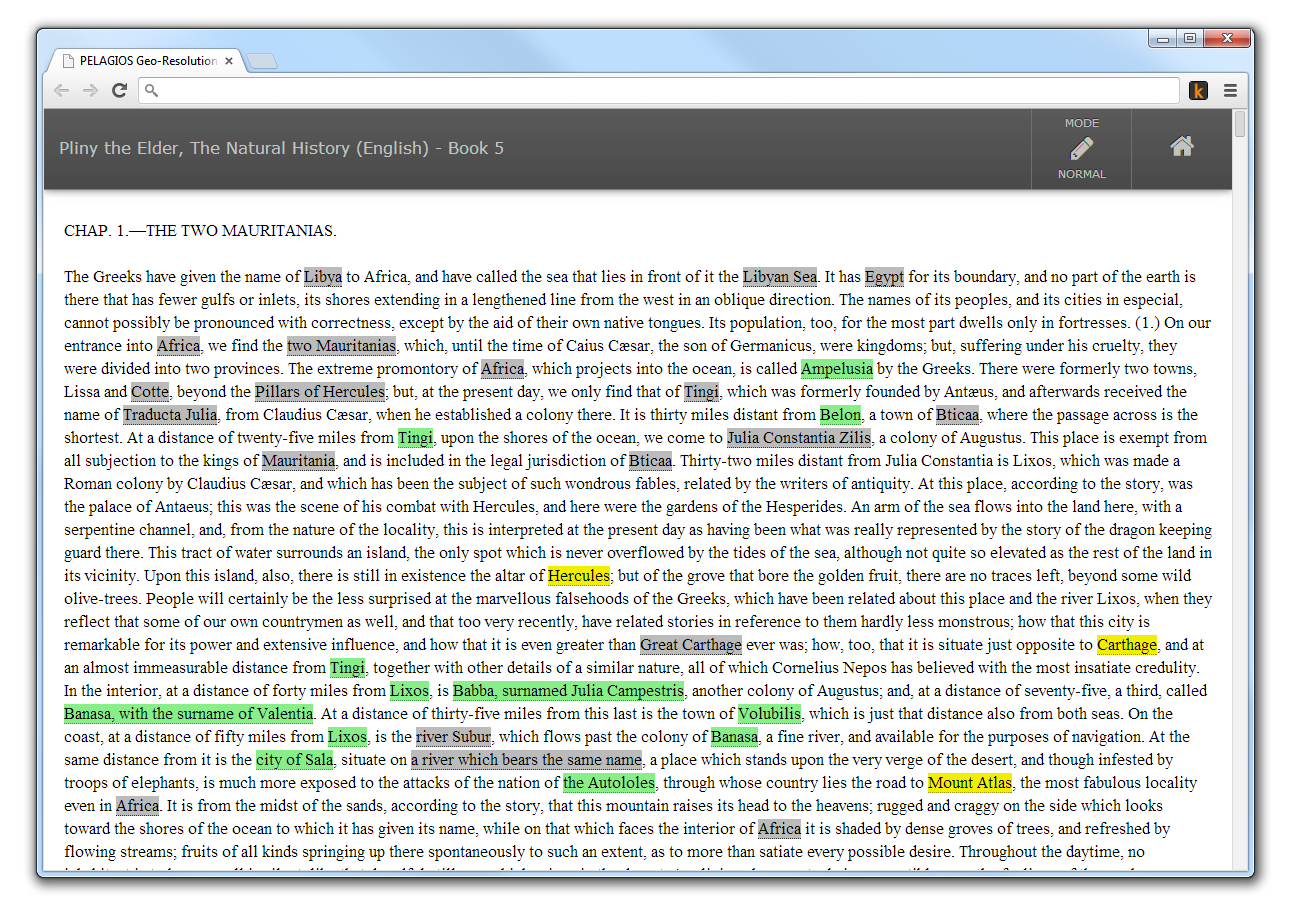
Fig. 2. Recogito text annotation interface.
The text annotation interface (see Fig. 2) is the place where we inspect and correct the results of geo-parsing - the automatic processing step that identifies toponyms in our source texts. Initially, when we start off with a new document, this view shows us our source text, marked up with grey 'highlights' wherever the geoparser thinks it has identified a toponym. We can then remove false matches, annotate toponyms the geoparser has missed, or modify things the geoparser got wrong (e.g. merge multiple identifications into one, turning separate consecutive identifications such as 'Mount' and 'Atlas' into a single toponym 'Mount Atlas').
Going through the source texts is a time-consuming task, and we have made every attempt to make the process as quick and painless as possible. The video above shows how the interface works in practice. Select text in the user interface as you would normally (using click and drag with your mouse, or double click), and confirm the action in the dialog window that pops up. Depending on what you select, the tool will automatically perform the appropriate action: either create a new annotation, delete one, or modify the annotation(s) in the selection. To speed up work even further, there is also an 'advanced' mode that skips the confirmation step.
There is one more thing you can see in Fig. 2: annotations are coloured to indicate their 'sign-off status'. We have already talked about this briefly in our previous post. It's a consequence of our practice to manually check every annotation before releasing it to the wild. Green annotations are those we have verified, and where we have confirmed a valid gazetteer ID). Yellow are the ones we've verified as valid toponyms - but for whatever reason we were yet unable to identify a suitable gazetteer ID for them. Grey are the ones we've either not looked at yet; or they are still 'work in progress' and we just haven't verified their gazetteer mapping.
Combined with the map-based interface you can think of this as creating the two parts of an annotation. The text annotation interface presents us with a reference to a place in a document (the 'target' of the annotation in Open Annotation terminology), while the map interface identifies a place in a gazetteer (the 'body' of the annotation). Although there are two steps to the process, they are fairly quick and easy. Maybe even fun!
1 "There's Plenty of Room at the Bottom" was a lecture given by physicist Richard Feynman in 1959. The talk is considered to be a seminal event in the history of nanotechnology, as it inspired the conceptual beginnings of the field decades later.





